Background
Onboarding Journeys can be long, more so if they’re for credit cards. The steps can be long drawn, they can lack clarity, and its very easy for users to get confused and dropoff entirely. Of course, this problem can be fixed by improving the UX but really understanding
- What confuses users
- Which users are most likely to dropoff
- Which steps are most likely to cause these dropoffs
Once we’ve figured out the answer for these questions, the next step is to act on these insights.
- Maybe send custom reminders and nudges to users that have dropped off
- Allow analytics teams to visualize real-time dropoffs though the journey
- Enable Product owners to analyze results of their A/B testing within the journey through real-time dashboards
These are some of the functionalities I wanted for my use-case while working on a funnel analysis of an onboarding journey. The answer to all of the above questions was an in-house event orchestration platform called Analytica (greek for science of analysis) that could power customer engagement tools, analytics, logging and basically anything that could require user triggered events.
Why application workflow engines just aren’t enough
All the steps and transitions in our onboarding journey were being powered by an application workflow engine. Usually all of the application and transition data is stored on a RDBMS/NoSQL Database. However its not possible to directly use this as a source of truth for analytics. First of all, you would need to gather all of this data from different sources and dump them in a warehouse to power analytics tools which in itself is a non-trivial task.
Once you manage to figure what data to store in your warehouse now you would have to do this all over again if you ever wanted to analyze funnels for a different onboarding journey which uses a different workflow engine. Having faced these challenges already, I wanted to create a platform where I could emit events that are completely independent from the workflow engine logic. This meant I could store any user metric that I wanted to store in whichever manner/format I wanted. The frontend could also now directly send me a clickstream data of user events (page visits, click activity, etc) and all of it could now be tracked without having to rely on whims of the workflow engine.
Customer Engagement aspect
As I had mentioned, a big part of clawing back dropped-off customers is to routinely send out engagement nudges based on internal logic. This meant using dedicated customer engagement tools that exist (e.g, Dittofeed) or developing your own for that matter. At the end of the day whichever route we decided to go, my idea for this platform was to be extensible above anything else. That meant while the event contracts between my platform and the event emitters were rigid, the engagement tool to be used for these events didnt have to be.
Real-time Analytics & Alerting
Since our platform relied on user events being emitted in real-time, this meant we could dump data into our warehouse in realtime which in turn meant we could connect BI Tools like Metabase or montoring tools like Grafana. This was a huge win specially since our existing methodology was to rely on time-lagged data sync jobs that would dump data to our warehouse. Suddenly it was possible to analyze dropoffs and raise alerts based on certain user activity thresholds in real-time.
The core design principles, and tackling scalability
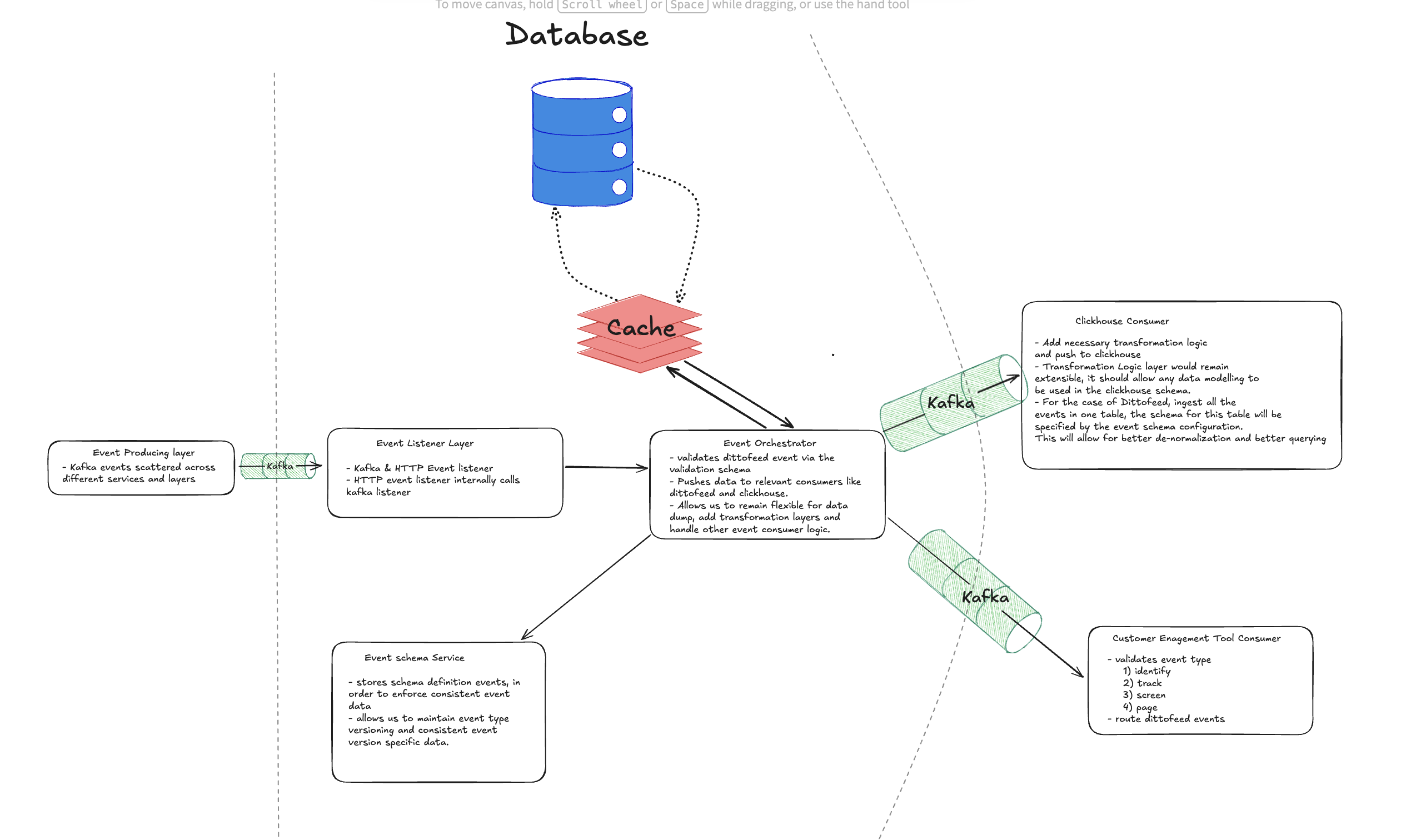
Extensibility above everything
Remember how I said my event contracts could be rigid? Well I lied, instead of relying on actual DTOs like API contracts, I would have validation schemas being fetched from the my platform’s database. This meant 2 things
- My service acted as the single source of truth for all the event schemas, this meant I could tell what event captures what data.
- I would not have to restart, recompile or redeploy my service even if an event schema changed, we could dynamically update the event schemas from the database as required.
These event schema contracts will be be defined with use of jsonschema python library which allowed us to enforce required and type validations in the contract. Any events non-conforming to the defined schema stored in the database would simply be rejected in this validation layer.
The Orchestrator Layer
Once the events had passed our validation layer, it was time for the orchestrator layer to send them our to the relevant consumers. What consumers you ask? Well the idea is simple, these consumers could be the downstream services (like warehouse, customer engagement and grafana) that are dependent on our user events. Since all consumers need not consume all events, this approach allowed us to configure only relevant events for specific consumers. This was achieved by introducing a transformation layer in between. Once validated, the orchestration layer would fetch relevant transformation configs from the db for this specific event type.
For example:
- For our warehouse consumer, we could define which fields are supposed to be mapped to what tables and what columns in the warehouse.
- For our customer engagement tool, we could define which underlying API to call for which specific event.
These transformation configs were stored as Jinja2 templates. This allowed us to leverage all the templating functionality like auto-populating timstamps, generating UUIDs that Jinja offered without having to configure transformation logic for every event seperately. This meant our transformation were consistent and always in a format that our consumers expected.
The Producer-Consumer Pattern
Staying true to our mantra of keeping everything extensible, we defined a consumer config table where all the consumer relevant configurations can be stored.
Addressing the elephant in the room - Scalability
As you could probably tell by now, the core problem my platform was about to face wasn’t that of extensibility, it was that of scalability. Handling the sheer amount of throughput arriving from several event streams could easily overwhelm our system. To tackle this, I had 2 major optimizations in mind.

Cache Validation and Transformation Configs: Constantly fetching them from the database added enormous amounts of overhead and latency that can easily be skipped by caching these configs. Although this could have been faster and easier with a manual Config implementation that keeps things in-memory, I decided to go with a Redis based approach which I would explain shortly why. Upon calling the schema update API, we would simply fetch and invalidate this cached schema. This feature along with a TTL would prevent our cache values from becoming stale.
Horizontally Scale EVERYTHING: If we simply de-coupled everything and relied purely on kafka for message queues, we could easily horizontally scale our system by simply adding more instances. This needed to happen for both, the central orchestration layer and the consumers. This meant all the consumers could be scaled completely independently. Since now we had multiple central orchestrator instances running, this meant we had to have a centralized cache store which is where Redis came into picture.
Both of these optimizations completely de-coupled our platform and allowed us to scale individual components independently. We would rely on industry proven, battle tested tools like K8s for auto-scaling, Kafka for load balancing and queues and finally Redis for Cache management. This allowed our platform to focus purely on the business logic and not have to manage scalability itself.
Performance Benchmarks and Final thoughts
Using the entries being created by our application workflow engine, I arrived at an approximate event production rate of 48-50 eps (Events per second) at peak times. Since my platform captured way more events than this, I went ahead with a 2x approximation factor and set a benchmark of 100 eps.
With just 3 small instances of my central orchestration layer and consumers each, I was easily able to scale up to 300 eps with sub 20ms latency (p95 <100ms). Since my approach was to rely on kafka, I was able to offload events from the central layer and store them in the consumer queues where my slower consumers could parse them at their own pace.
In future iterations, my plan is to implement batching in consumers for better throughput at the consumer end.
For now I was really satisfied with what I had achieved in terms of
- benchmarks (300 eps with built in resilliency and auto-scaling)
- in terms of functionality (we successfuly demo’d our customer engagement tool and warehouse analytics through this tool)
- in short timespan (2 weeks)
Designing and building this platform from scratch gave me a far deeper appreciation for distributed systems than any textbook ever could. Balancing extensibility with performance, schema flexibility with strict validation, and real-time guarantees with horizontal scalability forced me to think like both a product engineer and a systems engineer.
More than just handling events, this project taught me how to design decoupled architectures, leverage Kafka and Redis effectively, and build systems that can evolve without constant redeployments. Most importantly, it reinforced a key engineering lesson for me: scalability is not something you “add later” — it must be a first-class design principle from day one.